

The short answer: DataMapper uses advanced AI, including machine learning and large language models, to first structure raw data and then identify and validate sensitive content. As a result, sensitive information is identified with exceptionally high precision. This simplifies the clean up of files containing sensitive content while strengthening both the protection of sensitive data and the organisation’s compliance with GDPR.
Why finding sensitive expressions is so complex
Identifying sensitive information in an organisation’s data systems is a complex task, whether done manually or with specialised tools. There are several reasons for this. Here are just a few:
- The volume of data
A typical organisation will have millions of files, emails, attachments and documents. Reviewing this data manually is slow, imprecise and almost impossible to scale. - Context is crucial
A word or number only becomes sensitive when it relates to a person. For example, “COVID” or “Muslim” are not necessarily sensitive on their own, but in a sentence like “She was dismissed after saying she had COVID”, the context makes it sensitive under GDPR. - Sensitive data can hide anywhere
It is not only text documents that may contain sensitive content. Sensitive information can also be hidden in screenshots, scanned contracts, handwritten notes or photos of ID cards. Without assistance, every image must be reviewed manually, which is time consuming and based on our experience error prone. - Language and format complexity
Sensitive information can appear in many languages and in different national formats. A Danish CPR number looks different from a US Social Security Number, and even the same word can have different meanings depending on the language. - The evolution of sensitive expressions
Data protection regulations like GDPR are extensive and continuously updated. New risk terms emerge all the time. In addition, each organisation may have its own definitions of what is considered sensitive. - Technical limitations
Scanning complex documents such as Excel sheets with many rows and columns can be particularly challenging. OCR technology typically reads text vertically, but data in spreadsheets is often arranged in ways that do not fit this reading logic. This requires additional logic and advanced processing to accurately interpret and extract sensitive information from such structured documents.
To address these challenges, we have developed DataMapper.
Did you know that GDPR violations can result in fines of up to 20 million euros or 4% of the company's global annual turnover, whichever is higher
- European Commision
How does DataMapper search for sensitive data?
Unlike manual search, DataMapper uses an advanced search method that enables the solution to find sensitive data across millions of documents not over days or weeks, but in a matter of hours or even minutes, and with far higher precision.
Many other Data Discovery solutions can identify certain types of information using pattern matching or metadata filtering, but they often fall short when it comes to scanning images, multilingual documents or contextual analysis. This leads to missed risk files or an excess of false positives, creating unnecessary noise.
The search method in DataMapper consists of three phases, where data is processed with a distinct purpose in each phase to ensure that sensitive terms are ultimately identified both accurately and quickly. The three phases are:
- Preparation
- Analysis
- Validation
Need help managing personal data?
In our newsletter you get tips and tricks for dealing with privacy management from our founder Sebastian Allerelli.
When you sign up for our newsletter you get a license for one user to ShareSimple, which will give you a secure email in Outlook. This special offer is for new customers only, with a limit of one freebie per company.
1. Preparation
Before the search can begin, the material must be made searchable. DataMapper therefore starts by extracting and structuring the content so it can be analysed across file types and formats. This involves four processes carried out in the following order: Text Extraction, Optical Character Recognition (OCR), Language Detection and Text Indexing.

1.1 Text Extraction
The first step towards identifying sensitive data is gaining access to the text itself. In this phase, DataMapper begins by extracting all readable text from the files being scanned, whether they are standard text files or image based. If the document already contains selectable text, such as an email or a Word file, DataMapper extracts the text directly.
If the document is image based for example a scanned contract, a photo of an ID card or a screenshot of an email DataMapper automatically proceeds to the next step: OCR (Optical Character Recognition).

1.2 Optical Character Recognition (OCR)
All image based files are then converted by OCR technology into searchable text so they can be analysed in the same way as standard text based documents. Without this step, sensitive information embedded in such files would not be scannable.

1.3 Language Detection
Once the text has been extracted, DataMapper identifies the language. This is an important step that determines how the content is processed further. It is here the system decides which machine learning and AI models to apply based on the detected language. Think of it as placing each file on the correct processing line.
Words and numbers do not mean the same across languages. For example, “SSN” in English refers to a Social Security Number, while the equivalent in Denmark is a “CPR number”. Some sensitive data formats are also specific to certain languages or countries. A national identifier in one country may be completely irrelevant in another. By identifying the language from the outset, DataMapper ensures that each file is processed with the right language aware models, which makes subsequent keyword indexing, pattern recognition and context filtering far more accurate. If language detection is skipped, it will result in a significant number of false positives.

1.4 Keyword Indexing
When the text has been extracted and the language identified, DataMapper creates a complete index of all words and numbers in the scanned files. Every single term is evaluated against a carefully developed taxonomy of sensitive expressions. This taxonomy has been created together with legal and compliance experts and aligns with regulations such as GDPR.
The taxonomy covers three main categories of sensitive information:
- PII such as name, date of birth, national identification numbers
- Sensitive personal data such as health information, trade union membership, sexual orientation
- Business critical data such as contracts, budgets, documents relating to intellectual property
This taxonomy functions as a predefined vocabulary of risk markers and is continuously updated as legislation and data regulations evolve. But identifying keywords alone is not enough, which is why we take it a step further by using machine learning to validate patterns and reduce the number of false positives.
Stop the GDPR monster before it gets its hold of your personal data
2. Identification
Once the data has been prepared, DataMapper begins identifying potential occurrences of sensitive information, known as candidates. This is done by combining machine learning with RegEx patterns, which are matched against a taxonomy of relevant terms and concepts a taxonomy developed in collaboration with law firms and GDPR specialists. The goal is to identify all realistic candidates without generating unnecessary noise.


2.1 Machine Learning (ML) and Regular expressions (RegEX)
Many types of sensitive data follow recognisable patterns. For example:
- A credit card number is always 16 digits long.
- A social security number (SSN) might follow a XXX-XX-XXXX format.
- An IBAN (international bank account number) has a country-specific structure.
DataMapper uses RegEx to detect these patterns—but pattern matching alone isn’t enough. This is where machine learning (ML) steps in. ML models help DataMapper understand context and validate what the patterns actually mean in the surrounding text. They differentiate between a real social security number and, say, a phone number that just looks similar.
For example: If “555-55-5555” appears in a document, a simple pattern search might flag it as an SSN. But if it’s actually just a mistyped phone number, the ML model picks up on that and avoids a false positive. In short: ML adds the intelligence that rule-based systems lack—ensuring structured data isn’t just detected, but correctly understood.
3. Validation
In the final phase, each candidate is evaluated in its full context. This makes it possible to distinguish between genuinely sensitive information and harmless occurrences that merely resemble it. Here, DataMapper uses vectorisation of the data containing the sensitive information, followed by a Large Language Model to analyse the vector results.

3.1 Large Language Model (LLM)
Even after applying machine learning and pattern recognition, context remains crucial. Sensitive words and numbers can appear in situations where they are not actually sensitive. In such cases, they become what we call a false positive. This is where vectorisation and Large Language Models (LLMs) come into play. LLMs combined with data vectorisation enable DataMapper to go beyond pattern matching. They analyse the surrounding language and context to determine whether something is genuinely sensitive.
An example is:

A traditional RegEx search would flag the sentence “Jens has painted the picture Diabetes” as sensitive, because it contains the word “Diabetes”, which is classified as sensitive, and because there is a personal reference in the form of “Jens”. In this case, however, the LLM does not register any sensitive content because it evaluates the context. The reason is that “Diabetes” is mentioned in relation to a painting Jens has created, not as a medical condition affecting Jens or anyone else.
This example shows how DataMapper uses vectorisation and LLMs to understand context and distinguish between genuinely sensitive information and harmless occurrences. This reduces false positives and gives organisations a clear and accurate overview of which files actually require action.
From analysis to action
Once the data has passed through the three phases, DataMapper is left with a precise and validated overview of the files that actually contain sensitive content. The identified files are then presented directly in DataMapper’s interface in a list view that makes it easy for the user to understand, assess and act on the results.
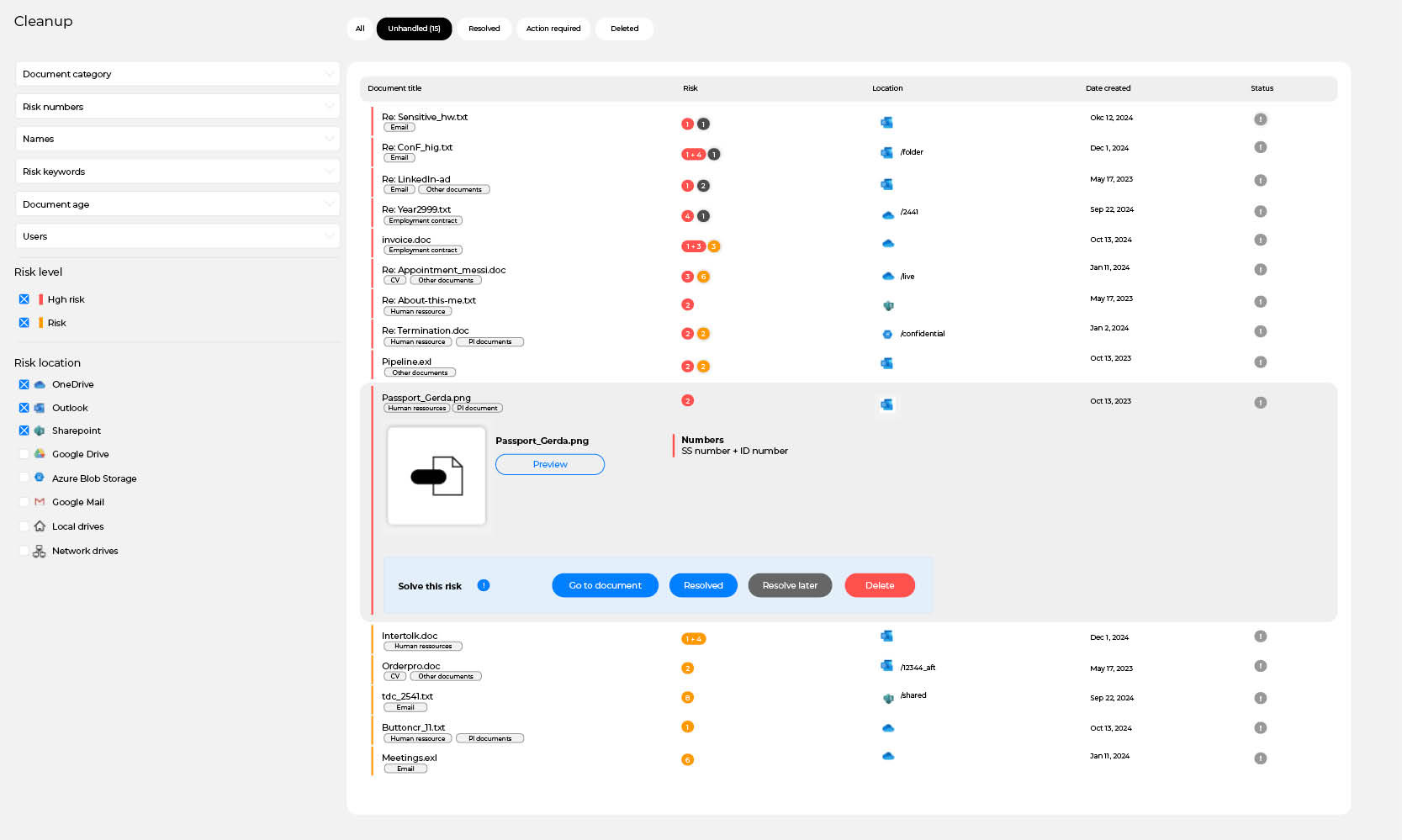
The user can open a preview of each file, making it possible to review every file in its full context. From the list view, the user can:
- delete the file if it should no longer exist
- move the file if it needs to be relocated to a more secure environment
- archive the file if it should be reviewed later
- approve the file if it no longer poses a real risk
The user no longer has to handle the enormous task of manually searching for risk files and trying to interpret raw search data. DataMapper’s search method is designed to make data cleansing, risk management and compliance practical and manageable. The result is that the organisation can quickly reduce its data risk, limit the exposure of personal information and document that GDPR is being complied with not just in theory, but in day to day practice.
FAQ on this topic
1. Can’t I just use a normal search function to find sensitive data?
A normal search doesn’t look inside images, PDFs, or detect context. It also returns tons of false positives, making compliance harder.
2. How does DataMapper know what data is sensitive?
It uses predefined taxonomies, machine learning models, and LLMs to understand context and validate results.
3. Will DataMapper’s search slow down my system?
No, DataMapper runs in the background without disrupting workflows.
4. Does DataMapper search in cloud storage?
Yes, it scans data across cloud services, emails, local storage, and more.
5. How does this method of searching help with GDPR compliance?
It ensures that all sensitive personal data is identified and managed correctly, reducing compliance risks.
The benefits of this search method
DataMapper’s search method is built on many years of experience analysing sensitive terms. It offers a smarter, faster and more compliant approach to the complex task of identifying sensitive data. In practice, DataMapper’s way of detecting sensitive terms provides several advantages:
- Saves time
Manual searching can take weeks or even months. DataMapper scans millions of files in hours or minutes and significantly reduces the time spent on data discovery. - Delivers greater accuracy
Using OCR, ML and LLMs, DataMapper avoids common errors and understands the context behind words and numbers. This combination of technologies helps prevent sensitive content from being overlooked while also reducing false positives. - Future-proof
The built-in taxonomy is developed with legal experts and continuously updated. This ensures that new terms that may emerge are found. - Customisable
You can remove or add sensitive terms to DataMapper’s taxonomy. This lets you tailor DataMapper to your organisation’s specific needs, whether it concerns terms unique to your industry, the type of data you handle, or a particular privacy policy you need to comply with.
Read more

Sebastian Allerelli
Founder & COO at Safe Online
Sebastian is the co-founder and COO of Safe Online, where he focuses on automating processes and developing innovative solutions within data protection and compliance. With a background from Copenhagen Business Academy and experience within identity and access management, he has a keen understanding of GDPR and data security. As a writer on Safe Online's Knowledge Hub, Sebastian shares his expertise through practical advice and in-depth analysis that help companies navigate the complex GDPR landscape. His posts combine technical insight with business understanding and provide concrete solutions for effective compliance.



