

Det korte svar: DataMapper anvender avanceret AI, herunder machine learning og large language models, til først at strukturere rådata og derefter identificere og validere følsomt indhold. Resultatet er, at følsomme oplysninger bliver identificeret med særdeles høj præcision. Dette letter oprydningen af filer med følsomt indhold samtidig med, at det styrker både beskyttelsen af følsomme data samt virksomhedens overholdelse af GDPR.
Hvorfor er det så svært at identificere følsomme udtryk?
Uanset om man søger manuelt eller bruger specialiserede værktøjer, er det en kompleks opgave at identificere følsomme oplysninger i virksomhedens datasystemer. Det skyldes flere årsager. Her er blot nogle af dem:
- Mængden af data
En virksomhed vil typisk have millioner af filer, e-mails, vedhæftninger og dokumenter. Det er en langsom, upræcis og næsten umulig proces at skalere, hvis man skal gennemgå disse data manuelt. -
Konteksten er afgørende
Et ord eller et tal bliver først følsomt, når det relaterer sig til en person. For eksempel er “COVID” eller “muslim” i sig selv ikke nødvendigvis følsomme, men i en sætning som “Hun blev opsagt efter at have fortalt, at hun havde COVID”, gør konteksten det følsomt ifølge GDPR. - Følsomme data kan gemme sig overalt
Det er ikke kun i tekstdokumenter der kan have følsomt indhold – følsomme oplysninger kan være skjult i skærmbilleder, scannede kontrakter, håndskrevne noter eller billeder af ID-kort. Uden hjælp skal hvert billede gennemgås manuelt, hvilket er både tidskrævende og – efter vores erfaringer – fejlbehæftet. -
Sprog- og formatkompleksitet
Følsomme oplysninger kan forekomme på mange sprog og i forskellige nationale formater. Et dansk CPR-nummer ser anderledes ud end et amerikansk social security number, og selv det samme ord kan have forskellig betydning afhængigt af sproget. -
Udviklingen af følsomme udtryk
Datalovgivninger som GDPR er omfattende og opdateres løbende. Nye risikotermer opstår hele tiden. Hertil kommer at hver virksomhed kan have sine helt egne definitioner af, hvad der betragtes som følsomt. -
Tekniske begrænsninger
Det kan være særligt udfordrende at scanne komplekse dokumenter som Excel-ark med mange rækker og kolonner. OCR-teknologi læser typisk tekst vertikalt, men data i regneark er ofte arrangeret på måder, der ikke passer til denne læselogik. Det kræver derfor ekstra logik og avanceret behandling for nøjagtigt at kunne tolke og udtrække følsomme oplysninger fra sådanne strukturerede dokumenter.
For at imødekomme disse udfordringer har vi udviklet DataMapper.
GDPR-overtrædelser kan give en bøde på op til 20 millioner euro eller 4% af virksomhedens globale årlige omsætning - alt efter hvad der er højest.
- Europa-Kommisionen
Hvordan søger DataMapper efter følsomme data?
I modsætning til manuel søgning benytter DataMapper en avanceret søgemetode, som gør løsningen i stand til at finde følsomme data på tværs af millioner af dokumenter – ikke over dage eller uger, men på få timer eller endda minutter. Og med langt højere præcision.
Mange andre Data Discovery-løsninger kan identificere visse typer information ved hjælp af mønstergenkendelse eller metadatafiltrering. Men de kommer ofte til kort, når det gælder scanning af billeder, flersprogede dokumenter eller kontekstanalyse. Det fører til oversete risikofiler eller et væld af falske positiver, hvilket skaber støj.
Søgemetoden i DataMapper består af tre faser, hvor data behandles med hvert sit formål for at sikre, at følsomme termer ultimativt identificeres både præcist og hurtigt. De tre faser er:
- Forberedelse
- Analyse
- Validering
Vil du have hjælp til at behandle persondata?
I vores nyhedsbrev du får tips og tricks til hvordan du lettere kan håndtere GDPR fra vores grundlægger Sebastian Allerelli.
Når du tilmelder dig vores nyhedsbrev, får du samtidig en gratis licens for én bruger til ShareSimple, som giver dig en e-mail i Outlook. Dette særlige tilbud er kun for nye kunder, med en grænse på én licens pr. virksomhed.
1. Forberedelse
Før søgningen kan begynde, skal materialet gøres søgbart. DataMapper starter derfor med at udtrække og strukturere indholdet, så det kan analyseres på tværs af filtyper og formater. Det omfatter fire processer som foregår i følgende rækkefølge; Text Extraction, Optical Character Recognition (OCR), Sproggenkendelse og Tekstindeksering

1.1 Text Extraction
Det første skridt mod at identificere følsomme data er at få adgang til selve teksten. I denne forbindelse starter DataMapper med at udtrække al læsbar tekst fra de filer, der scannes, hvad enten det er almindelige tekstfiler eller billedfiler. Hvis dokumentet allerede indeholder markerbar tekst (som i en mail eller en Word-fil), udtrækker DataMapper teksten direkte.
Men hvis dokumentet er billedbaseret – f.eks. en scannet kontrakt, et foto af et ID-kort eller et skærmbillede af en e-mail – går DataMapper automatisk videre til næste trin: OCR (Optical Character Recognition).

1.2 Optical Character Recognition (OCR)
Alle billedbaserede filer konverteres herefter af OCR-teknologi til søgbar tekst, så de kan analyseres på samme måde som almindelige tekstbaserede dokumenter. Uden dette trin ville følsomme oplysninger indlejret i ikke være mulige at scanne.

1.3 Sproggenkendelse
Når teksten er udtrukket, identificerer DataMapper sproget – dette er et vigtigt trin, der bestemmer, hvordan indholdet behandles videre i processen. Det er her, systemet afgør, hvilke machine learning- og AI-modeller der skal anvendes, baseret på det registrerede sprog. Tænk på det som at placere hver fil på det rette behandlingssamlebånd.
Ord og tal betyder nemlig ikke det samme på tværs af sprog – for eksempel henviser “SSN” på engelsk til et Social Security Number, mens det i Danmark svarer til et “CPR-nummer”. Nogle følsomme dataformater er desuden specifikke for sprog eller lande – en national identifikation i ét land kan være helt irrelevant i et andet. Ved at identificere sproget fra start sikrer DataMapper, at hver fil behandles med de rette sprogforstående modeller, hvilket gør den efterfølgende indeksering af nøgleord, mønstergenkendelse og kontekstfiltrering langt mere præcis. Hvis sproggenkendelse udelades, vil det resultere i en stor mængde falske positiver.

1.4 Indeksering af nøgleord
Når teksten er udtrukket og sproget identificeret, opretter DataMapper et komplet indeks over alle ord og tal i de scannede filer. Hvert eneste udtryk bliver gjort målbar op imod en nøje udarbejdet taksonomi af følsomme udtryk. Denne taksonomi er udviklet i samarbejde med juridiske og compliance-eksperter i overensstemmelse med eksempelvis GDPR.
Taksonomien dækker tre hovedkategorier af følsomme oplysninger:
-
Personhenførbare oplysninger (PII) – f.eks. navn, fødselsdato, CPR-nummer
-
Følsomme personoplysninger – f.eks. helbredsoplysninger, fagforeningsmedlemskab, seksuel orientering
-
Forretningskritiske termer – f.eks. kontrakter, budgetter, dokumenter om immaterielle rettigheder
Denne taksonomi fungerer som et foruddefineret ordforråd af risikomarkører og opdateres løbende i takt med, at lovgivning og dataforordninger udvikler sig. Men det er ikke nok kun at identificere nøgleord – derfor går vi et skridt videre og anvender maskinlæring til at validere mønstre og reducere mængden af falske positiver.
2. Identificering
Når data er forberedt, går DataMapper i gang med at identificere potentielle forekomster af følsomme oplysninger, såkaldte kandidater. Det sker ved at kombinere Machine Learning og RegEx-mønstre, der sammenholdes mod en taksonomi af relevante ord og begreber – en taksonomi der er blevet udviklet i fællesskab med advokathuse og GDPR-eksperter. Målet er at identificere alle realistiske kandidater, uden at der genereres unødvendig støj.


2.1 Machine Learning (ML) og Regular expressions (RegEx)
Mange typer følsomme data følger genkendelige mønstre. For eksempel:
-
Et betalingskortnummer består altid af 16 cifre
-
Et CPR-nr har formatet XXXX-XXXXXX
-
Et IBAN (internationalt bankkontonummer) har et landespecifikt format
DataMapper bruger RegEx til at identificere disse mønstre – men mønstergenkendelse alene er ikke nok. Her kommer Machine Learning ind i billedet. ML-modeller hjælper DataMapper med at forstå konteksten og validere, hvad mønstrene faktisk betyder i den omgivende tekst. De kan f.eks. skelne mellem et reelt personnummer og et telefonnummer, der blot ligner.
For eksempel: Hvis “1234-123456” står i et dokument, vil en simpel mønstergenkendelse muligvis markere det som et CPR-nr. Men hvis det i realiteten bare er et ubetydeligt nummer, vil ML-modellen fange det og undgå en falsk positiv. Kort sagt: Machine Learning tilføjer den intelligens, som regelbaserede systemer mangler – så strukturerede data ikke bare bliver opdaget, men også korrekt forstået.
3. Validering
I sidste fase vurderes hver kandidat i sin fulde kontekst. Det gør det muligt at skelne mellem faktisk følsomme oplysninger og uskyldige forekomster, der blot ligner. Her bruger DataMapper vektorisering af data med de sensitive informationer og derefter Large Language Model til analyse af vektor-resultaterne.

3.1 Large Language Model (LLM)
Selv efter brug af Machine Learning og mønstergenkendelse er konteksten stadig afgørende. Følsomme ord og tal kan optræde i sammenhænge som medfører, at de reelt ikke er følsomme. I så fald vil det være det vi kalder “en falsk positiv”. Det er her vektorisering og Large Language Models (LLM’er) kommer ind i billedet. LLM’er kombineret med vektorisering af data gør det muligt for DataMapper at gå skridtet videre end mønstergenkendelse. De analyserer det omkringliggende sprog og kontekst for at vurdere, om noget faktisk er følsomt.
Et eksempel er:

En traditionel RegEx-søgning ville markere sætningen “Jens har malet billedet Diabetes” som følsom, da der optræder ordet “Diabetes” i, som er et følsomt udtryk, og der samtidig optræder en personrelation i form af “Jens”. Men i dette tilfælde registrerer LLM’en ikke noget følsomt indhold, da den kigger på kontekst. Grunden til dette er at “Diabetes” nævnes i forbindelse med et billede, som Jens har malet og ikke som en reel medicinsk udtryk for noget Jens eller en anden fejler.
Eksemplet viser, hvordan DataMapper bruger vektorisering og LLM’er til at forstå konteksten og dermed skelne mellem reelt følsomme oplysninger og uskyldige forekomster. Det reducerer falske positiver og giver virksomheder et klart og præcist overblik over, hvilke filer der faktisk kræver handling.
Fra analyse til handling
Når data har gennemløbet de tre faser, står DataMapper tilbage med et præcist og valideret overblik over de filer, der faktisk indeholder følsomt indhold. De identificerede filer præsenteres herefter direkte i DataMappers interface i en listevisning, der gør det enkelt for brugeren at forstå, vurdere og handle på resultaterne:
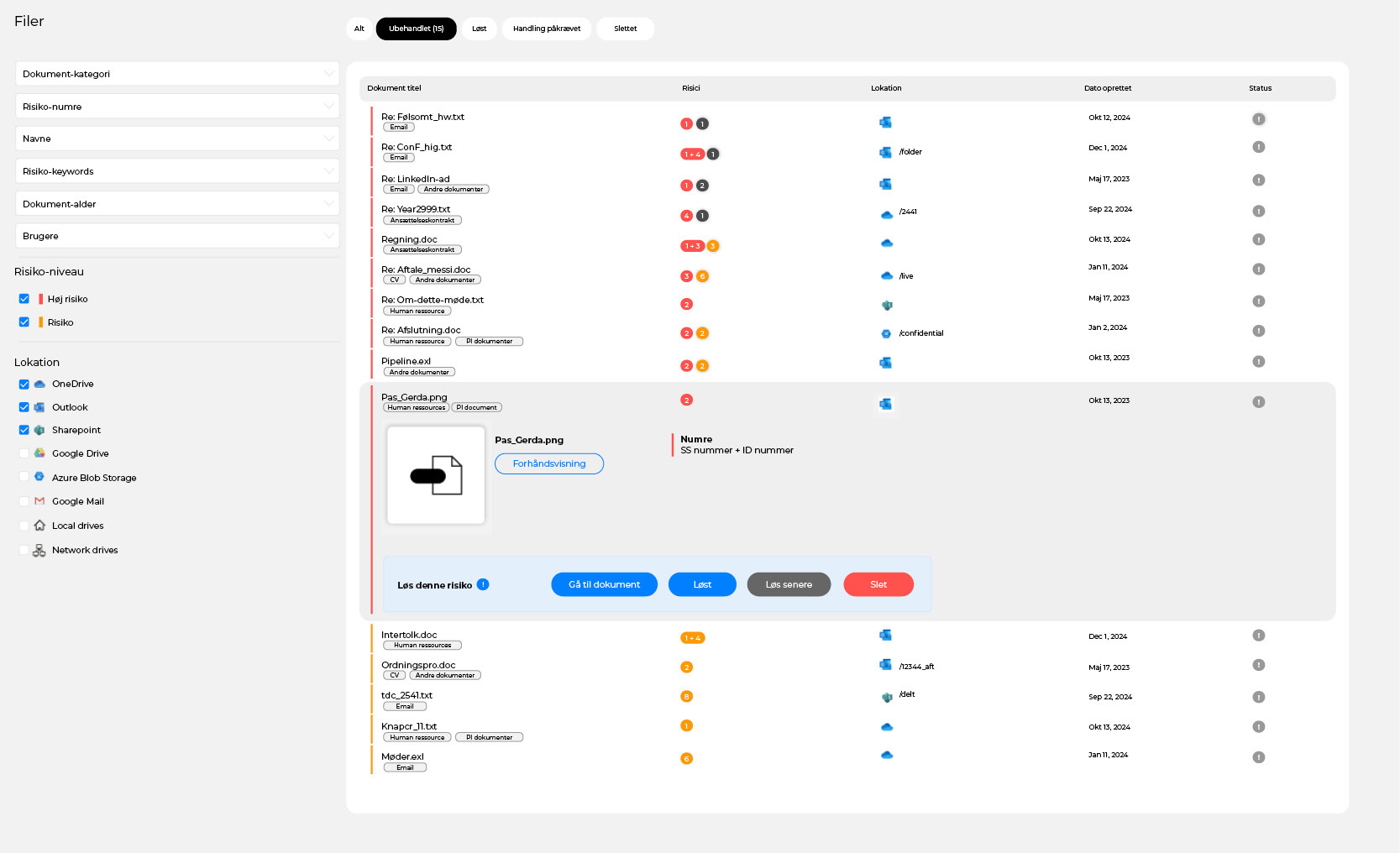
Brugeren kan tilgå en forhåndsvisning af den enkelte fil, der gør det muligt at gennemgå hver fil i dens kontekst. Fra listevisningen kan man:
-
slette filen hvis den ikke længere bør eksistere
-
flytte filen hvis den skal flyttes til et mere sikkert miljø
-
arkivere filen hvis du vil gennemgå den senere
-
godkende filen hvis den ikke længere udgør en reel risiko
Brugeren har nu sluppet for den ellers enorme opgave med manuelt at lede efter risikofiler og forsøge at tolke rå søgedata. DataMappers søgemetode er udviklet til at gøre datarensning, risikostyring og compliance praktisk håndterbart. Resultatet er, at virksomheden hurtigt kan reducere sin datarisiko, begrænse eksponeringen af personoplysninger og dokumentere, at GDPR overholdes — ikke kun i teorien, men i daglig praksis.
FAQ om DataMappers søgning
1. Kan jeg ikke bare bruge en almindelig søgefunktion til at finde følsomme data?
En almindelig søgning kigger ikke i billeder, PDF’er eller forstår kontekst. Den giver desuden ofte mange falske positiver, hvilket gør det sværere at overholde regler som GDPR.
2. Hvordan ved DataMapper, hvad der er følsomt?
Den bruger foruddefinerede taksonomier, machine learning-modeller og LLM’er til at forstå kontekst og validere resultater.
3. Gør DataMappers søgning mit system langsommere?
Nej, DataMapper kører i baggrunden og forstyrrer ikke eksisterende arbejdsprocesser.
4. Søger DataMapper også i cloud-lagring?
Ja, den scanner data på tværs af cloud-tjenester, e-mails, lokal lagring og meget mere.
5. Hvordan hjælper denne søgemetode med GDPR-compliance?
Den sikrer, at alle personfølsomme oplysninger bliver identificeret og håndteret korrekt, hvilket mindsker risikoen for brud på databeskyttelsesreglerne.
Fordelene ved DataMappers søgemetode
DataMappers søgemetode er udviklet gennem mange års erfaring med at analysere følsomme udtryk. Det er en smartere, hurtigere og mere compliant tilgang til den komplekse opgave det er at identificere følsomme data. Helt konkret giver DataMappers måde at identificere følsomme termer en række fordele:
- Sparer tid – Manuel søgning kan tage uger eller endda måneder. DataMapper gennemgår millioner af filer på få timer eller minutter og reducerer markant den tid, der bruges på datasøgning.
- Giver større præcision – Ved hjælp af OCR, ML og LLM’er undgår DataMapper typiske fejl og forstår konteksten bag ord og tal. Denne kombination af teknologier er med til at undgå at følsomt indhold bliver overset og giver samtidig færre falske positiver.
- Er fremtidssikret – Den indbyggede taksonomi er udviklet i samarbejde med juridiske eksperter og opdateres løbende. På denne måde er man sikker på, at nye udtryk, der måtte dukke op, bliver fundet.
- Kan skræddersyes – Man kan fjerne eller tilføje følsomme termer i DataMappers taksonomi. På denne måde kan man tilpasse DataMapper til éns virksomheds specifikke behov – hvadenten det gælder følsomme udtryk for éns branche, typen af éns data eller hvis man har en særlige privatlivspolitik, som skal efterleves.
Læs mere

Sebastian Allerelli
Grundlægger & COO hos Safe Online
Sebastian er medstifter og COO i Safe Online, hvor han fokuserer på at automatisere processer og udvikle innovative løsninger inden for databeskyttelse og compliance. Med en baggrund fra Copenhagen Business Academy og erfaring inden for identitets- og adgangsstyring har han en skarp forståelse for GDPR og datasikkerhed. Som forfatter på Safe Online's Videnshub deler Sebastian sin ekspertise gennem praktiske råd og dybdegående analyser, der hjælper virksomheder med at navigere i det komplekse GDPR-landskab. Hans indlæg kombinerer teknisk indsigt med forretningsforståelse og giver konkrete løsninger til effektiv compliance.



